Xin Ma
Biography
Welcome 👋 I am currently a Ph.D candidate at Monash University. Previously, I received the M.S degree from University of Chinese Academy of Sciences, where I studied at CRIPAC under the leadership of Prof. Tieniu Tan and was supervised by Prof. Ran He. Before that, I obtained the B.E degree from Jiangsu University. My research interests include image super-resolution and inpainting, model compression, face recognition, video generation, large-scale generative models, etc. I am always pursuing research collaborations on deep generative models for images and videos. Feel free to contact me if you are interested.
Work Experiences
Recent Publications





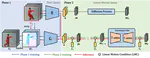
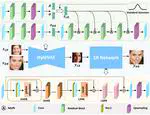
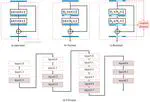

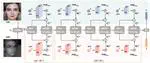

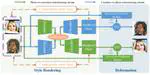
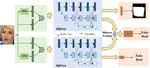

{kind=link}
Recent Projects


Granted Patents
-
Image super-resolution method of deep neural network fusing mutual information, CN110211035B
-
Attention-mechanism-based image completion method and device, CN112184582B
-
Cartoon style image conversion model training method, image generation method and device, CN112232485B
-
Image completion method based on uncertainty estimation, CN112686817B
Academic Activities
-
Conference Reviewers:
-
IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
-
International Conference on Acoustics, Speech and Signal Processing (ICASSP)
-
IEEE International Conference on Multimedia and Expo (ICME)
-
Chinese Conference on Pattern Recognition and Computer Vision (PRCV)
-
-
Journal Reviewers:
-
Signal, Image and Video Processing
-
IEEE Transactions on Circuits and Systems for Video Technology
-
International Journal of Computer Vision
-