Abstract
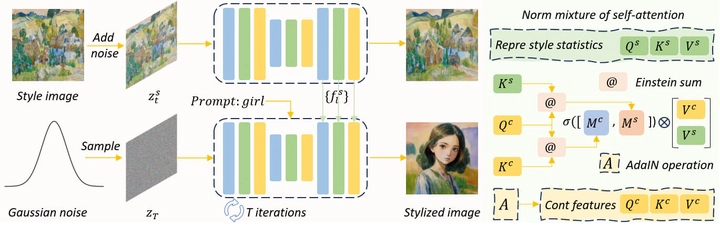
Although diffusion models exhibit impressive generative capabilities, existing methods for stylized image generation based on these models often require textual inversion or fine-tuning with style images, which is time-consuming and limits the practical applicability of large-scale diffusion models. To address these challenges, we propose a novel stylized image generation method leveraging a pre-trained large-scale diffusion model without requiring fine-tuning or any additional optimization, termed as OmniPainter. Specifically, we exploit the self-consistency property of latent consistency models to extract the representative style statistics from reference style images to guide the stylization process. Additionally, we then introduce the norm mixture of self-attention, which enables the model to query the most relevant style patterns from these statistics for the intermediate output content features. This mechanism also ensures that the stylized results align closely with the distribution of the reference style images. Our qualitative and quantitative experimental results demonstrate that the proposed method outperforms state-of-the-art approaches.
Xin Ma
PhD Student
I’m a Ph.D canditate at Monash University. My research interests include video and image generation, multimodal models, low-level vision, and face recognition, among others.
{kind=link}