Abstract
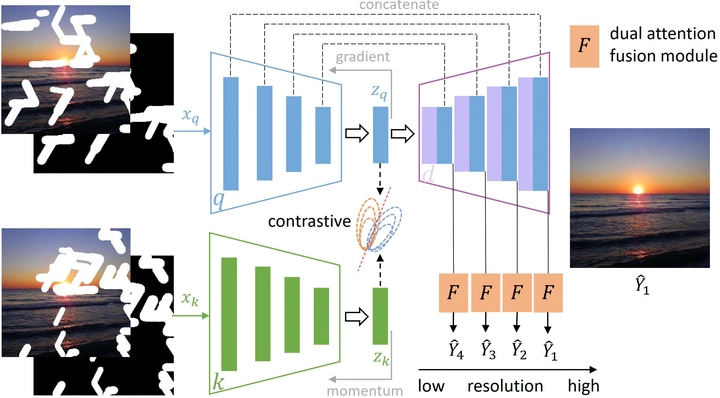
Most deep learning based image inpainting approaches adopt autoencoder or its variants to fill missing regions in images. Encoders are usually utilized to learn powerful representational spaces, which are important for dealing with sophisticated learning tasks. Specifically, in image inpainting tasks, masks with any shapes can appear anywhere in images (i.e., free-form masks) which form complex patterns. It is difficult for encoders to capture such powerful representations under this complex situation. To tackle this problem, we propose a self-supervised Siamese inference network to improve the robustness and generalization. It can encode contextual semantics from full resolution images and obtain more discriminative representations. we further propose a multi-scale decoder with a novel dual attention fusion module (DAF), which can combine both the restored and known regions in a smooth way. This multi-scale architecture is beneficial for decoding discriminative representations learned by encoders into images layer by layer. In this way, unknown regions will be filled naturally from outside to inside. Qualitative and quantitative experiments on multiple datasets, including facial and natural datasets (i.e., Celeb-HQ, Pairs Street View, Places2 and ImageNet), demonstrate that our proposed method outperforms state-of-the-art methods in generating high-quality inpainting results.
Xin Ma
PhD Student
I’m a Ph.D canditate at Monash University. My research interests include video and image generation, multimodal models, low-level vision, and face recognition, among others.
{kind=link}